I love LINQ. Especially since trying out Python, I find it a lot easier to think in terms of apply functions over iterators, rather than big loops with nested conditions. This has always worked really well for me. At least, it had done until yesterday, when we were tracking down a performance problem experienced when running through lots of buffers full of lots of data. Let’s take a look at two options for adding data to an internal list (this isn’t a realistic example, it’s just for profiling purposes):
private readonly List<ushort> _buffer = new List<ushort>();
public void Add(ushort[] data, int count) {
for (var i = 0; i < count; i++) {
_buffer.Add(data[i]);
}
}
public void AddLinq(ushort[] data, int count) {
_buffer.AddRange(data.Take(count));
}
data array has less than count elements. We could fix this by updating the condition used in the for of the first method, but the performance difference is negligible and it obscures what we are talking about.The Add method uses simple array traversal to add the first count elements to our internal _buffer list. The AddLinq method does the same thing, but uses the Enumerable.Take(x) extension method defined in System.Linq.
If you don’t think too hard about it you might assume these two have similarish performance. If I call both methods with a 10,000,000 element array and take the first 9,999,900 or so of those, I find the LINQ version takes around 370ms, while the non-LINQ version is around 135ms.
Now if this was in the context of a web page loading or for smaller amounts of data then I don’t think it’s going to bother anyone, but this is in the context of large amounts of data coming in every 20ms or so, so faster is better and taking almost 3 times as long is definitely a worry. Regardless of whether we care about this additional time, where exactly is it coming from?
Well the Take() extension method most likely uses something like this:
public static IEnumerable<T> Take<T>(this IEnumerable<T> data, int numberOfItemsToTake) {
var itemsTaken = 0;
foreach (var item in data) {
if (itemsTaken >= numberOfItemsToTake) yield break;
itemsTaken++;
yield return item;
}
}
If you’re not familiar with how yield return works under-the-hood, have a look at Raymond Chen’s discussion on the topic (Part 1,
Part 2, and
Part 3), and Jon Skeet’s article. Basically the compiler generates a class that implements IEnumerable<T> and IEnumerator<T>, and it keeps track of the state of the enumeration between yields from this method. With the overhead of another instance that has it’s own internal state machine to maintain, it’s never going to be as efficient as using a plain array index for state. Profiling two calls to each method gives the following:
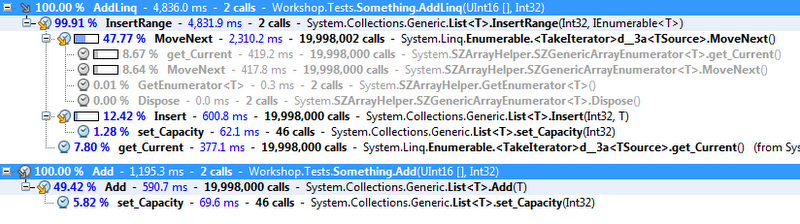
In both cases the actual list insertion of each element is about the same (the Insert and Add calls), around 600ms in total. In the non-LINQ case, this leaves about another 600ms for interating over the list using for and our integer index. In the LINQ case, we have a large amount of time (2,310ms) spent in MoveNext() on our compiler generated iterator (<TakeInterator>d__3a). You’ll notice that the slow MoveNext() call delegates to an SZGenericArrayEnumerator<T> which itself is reasonably fast, taking about 800 ms to iterate over the required elements compared with the 600ms of the non-LINQ version. The rest of the overhead is maintain the state machine, jumping between states and checking whether we have taken count number of elements yet. (It’s really interesting to step through this stuff with Reflector, try searching for <TakeInterator> with private/internal classes displayed if you want to see what goes on).
We ended up de-LINQing a couple of heavily used bits of code and solving most of the performance issues. Just remember that this is for a very specific scenario, and if you haven’t measured it, don’t optimise it away. But I think it is useful to have an idea of all the hard work happening under the hood of all that LINQy enumerable goodness.